
SHATRANJ.AI
An Artificial Intelligence Curriculum Based on Historic Board Games for Youth Development
Create a free account and log in to access our artificial intelligence curriculum across 25 topics, each with a downloadable ZIP package containing lesson materials, teacher guides, code notebooks, white papers, and more
Solve ancient challenges of the chessboard
Wheat and the Chessboard, Horse Tour, Eight Queens, Dilaram Mate, Suli’s Diamond
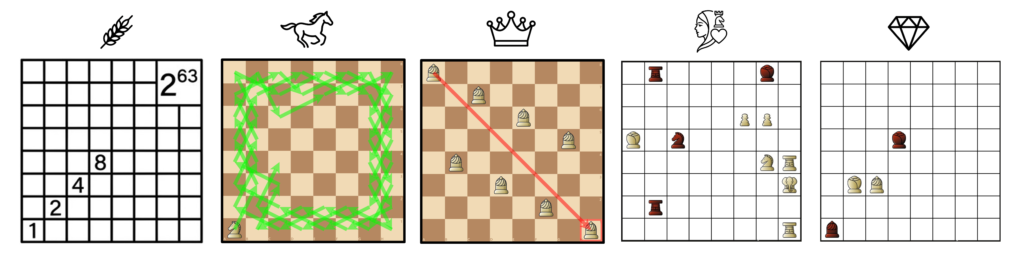
Study the historical progress of artificial intelligence algorithms
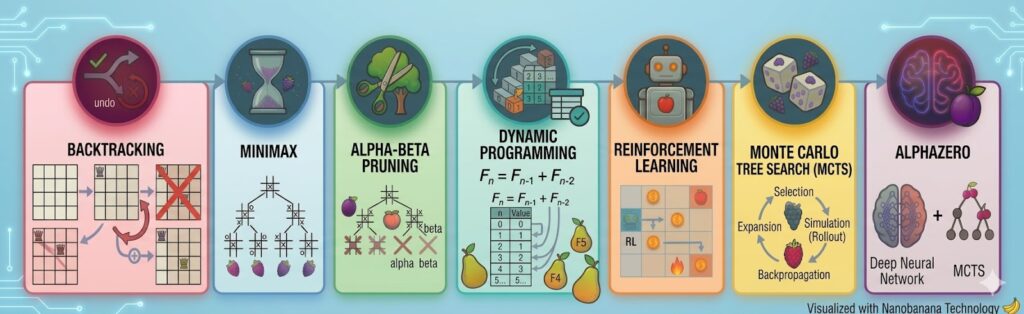
Master Artificial Intelligence through the evolution of chess AI software

AI Curriculum Based on Historic Board Games
25 structured lessons covering python, game programming, search algorithms, historic chess & AI puzzles, and modern AI, including Stockfish, reinforcement learning, MonteCarlo tree search, and AlphaZero
AI Curriculum Based on Historic Board Games
Lesson 1 – Project and Curriculum Scope and Priorities
Summary: Introduces Shatranj.AI project, Erasmus+ foundations, partner organizations, digital platforms.
- Introduces the Shatranj.AI project, its Erasmus+ foundations, partner organizations, and digital platforms.
- Project vision, Erasmus KA2 context
- Partner institutions and cultural heritage focus
- Overview of platforms (editor, LMS, code tools)
- Teacher roles and student outcomes
- Curriculum structure overview
- Python/Jupyter introduction
Lesson 2 – Computing & Python Setup
Basic computing concepts and Python/Jupyter installation.
Login required to access full content.
- Students learn core computing concepts and set up Python/Jupyter.
- CPU, RAM, I/O basics
- Bits, bytes, binary representation
- JupyterLab installation
- First Python notebook execution
- Variables, simple expressions
- Access to Drive folders
Lesson 3 – Python Data Types
Numbers, strings, lists, and essential data handling in Python.
Login required to access full content.
- Covers Python’s built‑in data types and basic operations.
- Integers, floats, strings, booleans
- Type conversion
- Lists and indexing
- Mutability concepts
- Chess-pieces-as-strings exercises
Lesson 4 – Conditionals, Loops, Control Flow
If/else logic, loops, and control flow fundamentals.
Login required to access full content.
- Introduces logic, loops, and interactive programs.
- If/elif/else logic
- Boolean operations
- For/while loops
- Break/continue
- Simple input programs
Lesson 5 – Functions, Scope, Lambda
Writing functions, parameters, returns, and variable scope.
Login required to access full content.
- Teaches modular code with functions.
- Defining functions
- Parameters and returns
- Local/global scope
- Lambdas
- Small functional project (piece-value calculator)
Lesson 6 – Files, Exceptions, Libraries, Testing
Reading/writing files, handling errors, and using libraries.
Login required to access full content.
- Working with files and robust code.
- File read/write
- Try/except
- Importing libraries
- Simple testing
- Handling invalid inputs
Lesson 7 – OOP, Classes, TicTacToe
Classes, objects, and building a simple TicTacToe game.
Login required to access full content.
- First exposure to OOP.
- Classes and objects
- Attributes and methods
- Game modeling
- TicTacToe implementation
- Debugging OOP code
Lesson 8– Chess & Shatranj Code Foundations
Board representation and basic piece movement logic.
Login required to access full content.
- Students start building engine components.
- Board representations
- Piece movement basics
- UTF-8 rendering
- Chess board editor tools
- Printing and moving pieces
Lesson 9– Chess & Shatranj Code Foundations
Board representation and basic piece movement logic.
Login required to access full content.
- Students start building engine components.
- Board representations
- Piece movement basics
- UTF-8 rendering
- Chess board editor tools
- Printing and moving pieces
Lesson 10– Search Algorithms / Adversarial Search
DFS, BFS, UCS, and A* search foundations.
Login required to access full content.
- Core AI search algorithms for games.
- Search problem structure
- DFS, BFS, UCS
- A* and heuristics
- Minimax introduction
- Pacman/chess examples
- Graph-tracing exercises
Lesson 11 – Search Algorithms / Adversarial Search
Minimax basics with chess/Pacman examples.
- Core AI search algorithms for games.
- Search problem structure
- DFS, BFS, UCS
- A* and heuristics
- Minimax introduction
- Pacman/chess examples
- Graph-tracing exercises
Lesson 12 – Horse Tour (Knight’s Tour)
Recursion, backtracking, and heuristic solutions.
Login required to access full content.
- Explores Knight’s Tour with recursion and heuristics.
- Knight graph movement
- Open/closed tours
- Backtracking with DFS
- Warnsdorff heuristic
- Connection to TSP
Lesson 13 – Eight Queens Puzzle
Backtracking and constraint-based problem solving.
Login required to access full content.
- Constraint satisfaction with backtracking.
- Queen attack logic
- Recursive search
- Optimization techniques
- Historical queen references
- Notebook implementations
Lesson 14 – Wheat & Chessboard Problem
Exponential growth and classic logic puzzles.
Login required to access full content.
- Mathematical puzzles and exponential growth.
- Doubling on chessboard
- Powers of 2
- Magic squares
- Smullyan logic puzzles
Lesson 15 – Minimax, Alpha-Beta, Checkmate Logic, Dilaram and Rumi mates
Advanced search, pruning, and endgame logic.
Login required to access full content.
- Deep adversarial search and chess endgames.
- Minimax computation
- Alpha-beta pruning
- Opposition, triangulation
- Historical sources (Al-Adli, Reti)
Lesson 16 – Suli’s Diamond (Dynammic Programming))
Historic endgame study and triangulation.
Login required to access full content.
- Historic chess endgame analysis.
- Al-Suli biography
- Reconstruction of endgame
- Opposition and triangulation
- Corresponding squares theory
Lesson 17 – Stockfish as the modern chess AI software
Adapting classical engines to play Shatranj.
Login required to access full content.
Explores how modern chess engines evolved and how open-source engines can be adapted to historical variants.
- Deep Blue’s brute-force hardware search
- Rybka and the rise of evaluation-centric engines
- Stockfish as an open, community-driven engine
- How Stockfish represents pieces, moves, and rules
- Modifying piece movement (ferz, wazir), evaluation, legality rules
- Building Shatranj-compatible search and evaluation
Lesson 18 – Reinforcement Learning Foundations: Gridworld, Dynamic Programming, and Complexity
Rook pathfinding and reinforcement learning basics.
Login required to access full content.
Introduces RL concepts using a simple OpenAI Gym–style gridworld based on rook movement.
- Agent–environment loop
- States, actions, rewards, episodes
- Q-learning and ε-greedy exploration
- Rook navigation on an 8×8 board
- Reward shaping and sparse reward issues
- Visualizing policy improvement step-by-step
Lesson 19 – The Frozen Rook: Tabular Q-Learning on FrozenLake
Which games can be built using reinforcement learning.
Login required to access full content.
Overview of small, medium, and complex games that students can use to implement RL algorithms.
- TicTacToe, Connect-4, Gridworld
- Snake, Pacman, Othello/Reversi
- Mini-chess and other board variants
- State space vs. reward density considerations
- Matching games with RL methods (Q-learning, MC, DQN, MCTS)
- Choosing project-friendly RL environments
Lesson 20 – Two Rooks vs Lone King: Learning Checkmate with Temporal-Difference Q-Learning
Training an RL agent to perform classical checkmate.
Login required to access full content.
Applies RL to a structured chess endgame where the agent must learn the coordinated 2-rook mating pattern.
- Environment design and state encoding
- Sparse rewards and reward shaping for endgames
- Learning piece coordination and zugzwang patterns
- Progressive improvement through self-play
- Visualizing trajectories toward checkmate
- Bridge to AlphaZero-style self-play and value learning
Lesson 21 – Deep Q-Networks: From Q-Tables to Neural Networks
MCTS, neural networks, and building mini-AlphaZero.
Login required to access full content.
Minimax & Alpha-Beta (bridging classic AI and RL)
- Why pure RL struggles with deep tactics
- Why humans and engines search
- Teach minimax, alpha-beta
- Connect to MCTS logic (search tree with value estimates)
- Very important bridge: AlphaZero = RL + MCTS + neural nets
Introduction to policy/value functions
- States → value
- States → probability distribution over moves
- Explain why tabular methods fail in full chess
- Show that we need function approximation
- Introduce NNEU concept here:
What is NNEU?
– neural network evaluation unit
– a neural net replacing hand-coded evaluation
– outputs value (who is better)
– outputs policy (what moves are likely good)
The students don’t need deep math; only intuition
Deep Q-Learning (DQN) with simple games
- Use Snake or Catch
- Teach replay buffer, target network
- Show why DQN does NOT work for chess (action space too large), preparing AlphaZero.
Policy gradient & actor-critic basics
(Short overview, not too mathematical)
- Policy gradient: learn policy directly
- Actor-critic: policy (actor) + value estimate (critic)
- Prepare students for AlphaZero’s architecture (policy + value output).
Monte Carlo Tree Search (full lesson)
- Expand nodes
- Simulate
- Backup values
- Choose action using visit counts
- Show how policy prior improves MCTS
- Show how MCTS improves the policy network → the AlphaZero training loop emerges
Putting it all together: the AlphaZero algorithm
- Self-play generates games
- MCTS guided by neural net creates improved policy
- Neural net trained on (state, policy_targets, value)
- Iteration of self-play → training → stronger MCTS → stronger games
- Show how AlphaZero solves simple mini-chess (4×4, 5×5)
- Connect back to your 2-rook checkmate lesson
Students now understand:
– how RL can solve small tasks
– why full chess needs powerful NNEUs, MCTS, and self-play
Build a mini AlphaZero for Connect-4 or MiniChess
- Connect-4 board is perfect for classroom AlphaZero demo
- Implement:
– neural net (small CNN or MLP)
– MCTS
– self-play training
Lc0 is a direct open-source implementation inspired by DeepMind's AlphaZero project, and it has far exceeded its success in chess.
https://lczero.org/
Lesson 23 – AlphaZero on Othello/Reversi
Upgrades MCTS into AlphaZero-style search by adding a neural network that supplies a policy prior and a value estimate, then trains through self-play.
- Bridge intuition with a tiny ‘Connect2’ AlphaZero demo, then transfer the ideas to Othello.
- Replace UCT with PUCT: combine visit statistics with a learned policy prior to guide exploration.
- Neural network heads: policy (move probabilities) and value (position evaluation) used in place of random rollouts.
- AlphaZero loop: self-play → training targets (π, z) → network update → repeat; evaluate via tournament matches/logs.
- Path-aware move encoding for variable-length capture sequences so different capture paths remain distinct.
Lesson 24 – AlphaZero on Qirkat: PUCT, Policy/Value Nets, and Self-Play
Upgrades MCTS into AlphaZero-style search by adding a neural network that supplies a policy prior and a value estimate, then trains through self-play.
- Bridge intuition with a tiny ‘Connect2’ AlphaZero demo, then transfer the ideas to Qirkat.
- Replace UCT with PUCT: combine visit statistics with a learned policy prior to guide exploration.
- Neural network heads: policy (move probabilities) and value (position evaluation) used in place of random rollouts.
- AlphaZero loop: self-play → training targets (π, z) → network update → repeat; evaluate via tournament matches/logs.
- Path-aware move encoding for variable-length capture sequences so different capture paths remain distinct.
Lesson 25 – Turkish Checkers (Dama): Alpha-Beta, PUCT-guided MCTS, Alpha Zero
Implements Turkish Checkers and compares classical search (alpha–beta) with MCTS using a reusable match runner and batch simulation logs.
- Game engine: board representation, legal moves with multi-jump captures, and move-path encoding.
- Evaluation function plus Negamax/Alpha-Beta search agent; depth vs strength tradeoffs.
- MCTS agent for Turkish Checkers and head-to-head comparisons against alpha–beta.
- Universal match runner (play_game) and batch simulation utilities for reproducible experiments.
Exportable logs (zipped) for classroom review and debugging.